A Python script for taking full-page screenshots of many webpages
A way to gain perspective on a web build.

In some of my early art school classes, my professors stressed the importance of "taking a step back from the work." It's easy to get absorbed in the details—the shading in this corner, the color in this square centimeter—but you have to step back to see if the composition is working together as a whole.
When you step back, it's easy to see which places are over- or under-worked and where you need to focus your efforts to make the piece pop.
It's easy to step back from a physical piece—you literally just have to walk away from the drafting table or easel to get a new vantage point. It's harder when designing a website because you can pull up only so many pages on a screen.
So how can you get a new vantage point on a website? You could manually take screenshots of all the pages or use a paid service, but it's possible to get the results you need with a Python script.
I don't think this counts as "vibe coding," but several months ago, I used ChatGPT to cobble together a Python script that can take full page screenshots of a website in both desktop and mobile view. This script has been extremely helpful for getting a 30,000 foot view of a website's design and visual cohesion (or lack thereof) quickly and easily.
I've used it to take full-page screenshots of more than 30 webpages on a single site and also to capture images from sites in similar verticals, which is useful for benchmarking design ideas and collecting ideas, best practices, and examples of what to avoid.
How to use the script
It's pretty simple to use. All you need to do is:
- Add a folder name where you want the images saved.
- Drop in a list of web URLs that you want screenshots of
- Run the script using
python3 website_screenshots.py
This post assumes:
Even if you have to do a little bit of config work to get things going, this is a great way to have practical experience with the command line and add a tool to your web design toolkit.
Getting the list of URLs
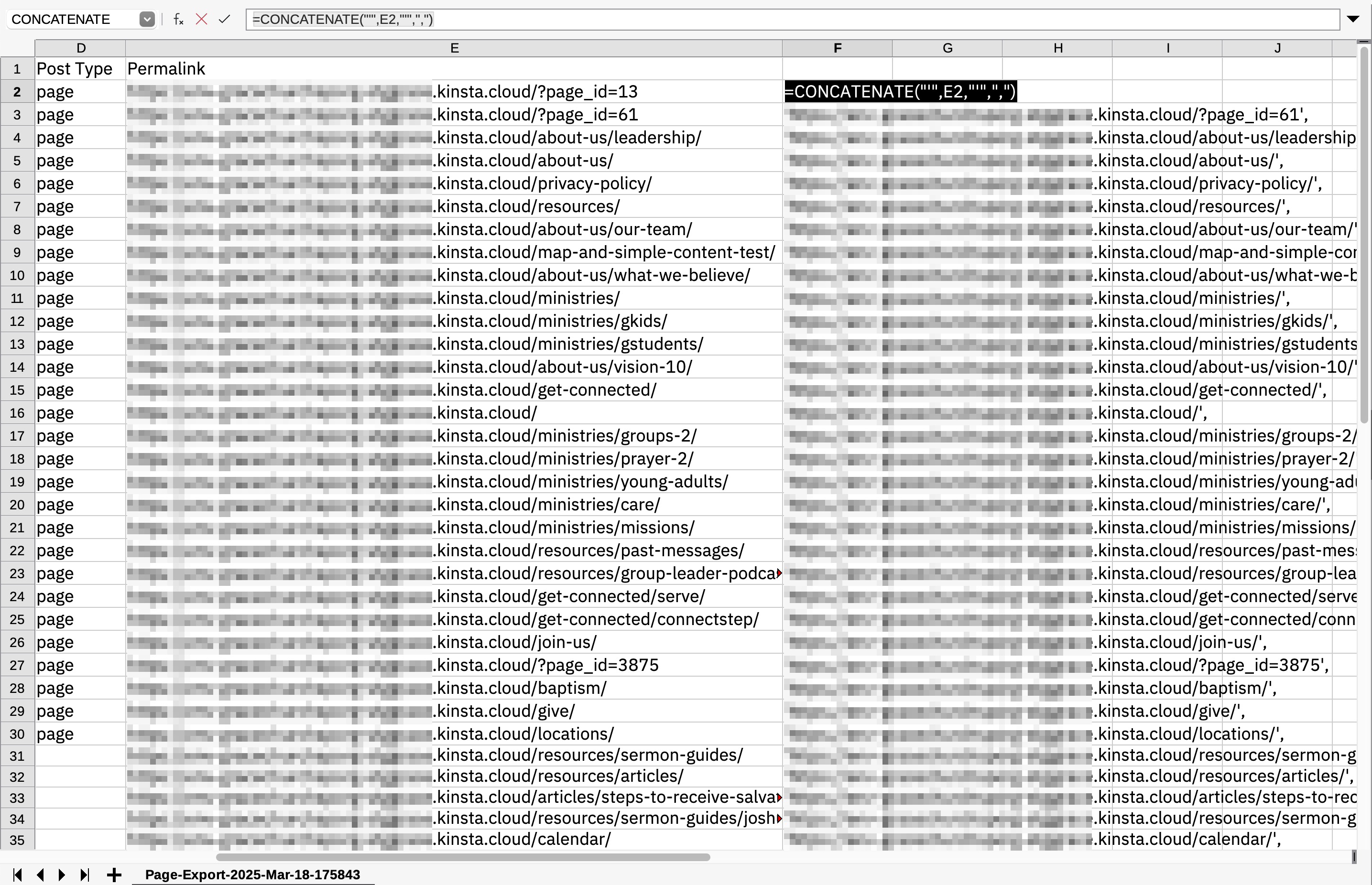
My use case is working with WordPress sites, so it's easy to export a CSV of the desired URLs with WP Import Export Lite. From there, I can use a CONCATENATE function to add the necessary quotes and commas for correct Python syntax:
=CONCATENATE("'",E2,"'",",")You could also manually copy/paste the links into a spreadsheet (as in the case of competitor websites) and still use the CONCATENATE function.
Using the screenshots
The script runs in the background and displays logging information in the terminal so you have an idea of how far along things are in the process. Once the screenshots are complete, it's easy to drag them into Figma, apply a standard width to all of the imported images (Figma does some arbitrary resizing), and then arrange them in a sensible order for review.
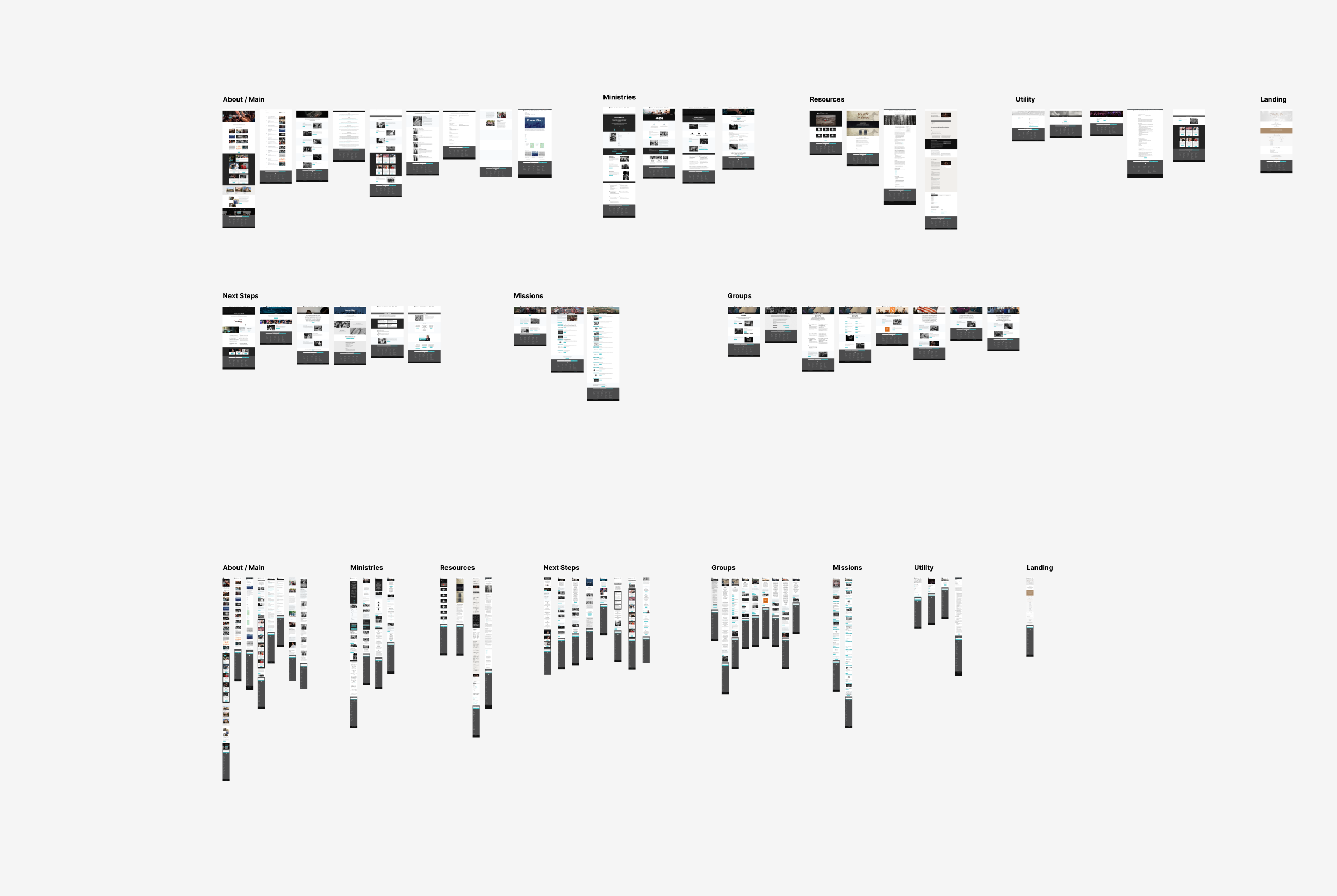
In my experience, this approach has helped me identify:
- fundamental design issues in an existing website
- type sizing inconsistencies across pages
- spacing issues and inconsitencies
- missing content sections and features
- opportunities for improved UI elements
- and more
Known limitations
There are some known limitations to the script, so your results may vary. The two main issues I've encountered involve:
- Pages where the hero image/video is set to 100vh. The script produces a really long screenshot that's just a stretched version of the hero without any content below. I think this has to do with the fact that it's running in headless mode (meaning it doesn't actually open the browser), which seems to influence page rendering. In these cases, I just use the screenshotting tool built-in to Firefox.
- Pages with lots of elements that lazy load / animate on scroll. The script scrolls down the page, and a wait time (in seconds) can be set. The default is 5, but gone has high as 10 seconds, which should give just about any webpage plenty of time to fully load. But sometimes some elements will be missing—even with scrolling down and including time for all elements to load. In those cases, a manual screenshot might be best.
Full script
Use the script below and test it out for yourself. I hope this helps you as much as it's helped me!
import logging
import os
import re
import time
from urllib.parse import urlparse
from selenium import webdriver
from selenium.webdriver.firefox.service import Service
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# Set up logging
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler("website_screenshots.log"),
logging.StreamHandler()
]
)
# Set up Firefox options
firefox_options = Options()
firefox_options.add_argument("--headless") # Run in headless mode
# Path to GeckoDriver (update this if needed)
geckodriver_path = "/usr/local/bin/geckodriver"
# Set up WebDriver
driver = webdriver.Firefox(service=Service(geckodriver_path), options=firefox_options)
# Create a main folder for screenshots — change website_screenshots to another name if desired
folder_path = os.path.join(os.path.expanduser("~"), "Desktop", "website_screenshots")
os.makedirs(folder_path, exist_ok=True)
# Function to wait until page is fully loaded
def wait_for_page_load(driver, timeout=10):
WebDriverWait(driver, timeout).until(
lambda d: d.execute_script("return document.readyState") == "complete"
)
# Function to sanitize filenames (remove special characters)
def sanitize_filename(name):
return re.sub(r'[<>:"/\\|?*]', '_', name) # Replace invalid filename characters with "_"
# Function to extract a page slug from the URL
def extract_page_slug(url):
parsed_url = urlparse(url)
domain_part = parsed_url.netloc.split('.')[1] # Extract domain name
path = parsed_url.path.strip('/').replace('/', '-') # Convert "/" to "-"
if not path: # If it's the homepage
path = "home"
return sanitize_filename(f"{domain_part}_{path}")
# Function to take a full-page screenshot
def take_full_page_screenshot(url, save_path, viewport_width, viewport_height, viewport_name):
logging.info(f"Capturing {url} at {viewport_width}x{viewport_height}...")
# Set browser size and open the page
driver.set_window_size(viewport_width, viewport_height)
driver.get(url)
wait_for_page_load(driver)
time.sleep(5) # Extra wait time for content to load — increase/decrease this number as needed
# Scroll to the bottom to ensure lazy-loaded content appears
page_height = driver.execute_script("return document.body.scrollHeight")
logging.info(f"Page height: {page_height}")
driver.set_window_size(viewport_width, page_height) # Adjust viewport
time.sleep(5) # Ensure all elements have loaded
# Ensure save folder exists
os.makedirs(save_path, exist_ok=True)
# Generate the filename
filename_prefix = extract_page_slug(url)
filename = f"{filename_prefix}_{viewport_name}.png"
# Save the screenshot
full_save_path = os.path.join(save_path, filename)
with open(full_save_path, 'wb') as f:
f.write(driver.get_screenshot_as_png())
logging.info(f"Screenshot saved: {full_save_path}")
# List of URLs to capture
urls = [
"https://example.com",
"https://example.com/contact-us",
"https://example.com/about/team"
]
# Define viewports for desktop and mobile
viewports = {
"desktop": {"width": 1920, "height": 1080},
"mobile": {"width": 375, "height": 667} # iPhone 6/7/8 dimensions
}
# Loop through URLs and viewports
for viewport_name, dimensions in viewports.items():
for url in urls:
domain_folder = os.path.join(folder_path, urlparse(url).netloc)
os.makedirs(domain_folder, exist_ok=True) # Ensure domain folder exists
start_time = time.time()
take_full_page_screenshot(url, domain_folder, dimensions["width"], dimensions["height"], viewport_name)
end_time = time.time()
logging.info(f"Time taken for {url} ({viewport_name}): {end_time - start_time:.2f} seconds")
# Close WebDriver
driver.quit()